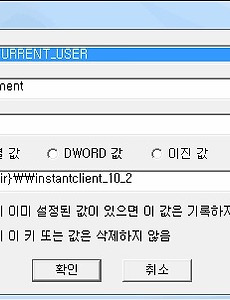
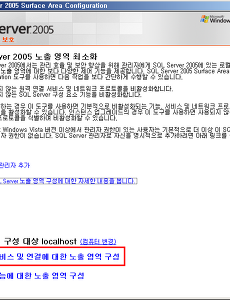
프로그래밍/DB/DB45 인스톨팩토리 + 오라클 인스턴트 클라이언트 작업시 오라클 인스턴트 클라이언트를 인스톨 팩토리로 배포 할 경우 위와같이 개인사용자 환경변수 등록이 가능하다. 또 간혹 오라클 캐릭터 셋이 안맞는 경우가 존재하는데 그럴때는 다시 키값을 하나 추가한 후 값의 이름을 NLS_LANG, 값을 KOREAN_KOREA.KO16MSWIN949 이런식으로 맞추어서 넣어주면된다. 조금더 오라클 관련 값을 추가 하고 싶다면 http://blog.naver.com/oct8?Redirect=Log&logNo=100042831960 링크를 확인 바란다. 2010. 12. 9. [MSSQL] 프로시저의 예외 처리 프로시저의 예외처리 및 새로운 기능 MSSQL2005 : http://cafe.naver.com/ebasenet.cafe?iframe_url=/ArticleRead.nhn%3Farticleid=169 예외처리 사용 방법 : 분기문의 마지막 시간이다. TRY..CATCH MSSQL 2000에서 주로 사용되던 @@ERROR함수를 2005부턴 거의 사용할 필요가 없게 해주는 예외처리 분기문이다.(하지만 알고는 있어야 한다...;;;) .NET이나 java등에서도 동일하게 사용되니... 역시나 VB6(VBA)에서 goto문만 알고 있는 개발자면 어찌되었건 불리하다. 구문은 심플하다. BEGIN TRY 실행구문~~ END TRY BEGIN CATCH 예외처리~~ END CATCH 대표적인C#에서표현해보자믄...... 2010. 11. 25. [MSSQL] 말일 구하는 방법 참조블로그 : http://blog.naver.com/urlham/100065338331 2010. 11. 25. 인덱스 관련 [인덱스]-색인 책에서 원하는 내용을 빨리 찾으려면 인덱스를 이용(책의 인덱스와 비슷한 개념) DB도 사용자가 원하는 내용을 빨리 찾으려면 색인이란 정보를 미리 만들어서 원하는 데이터를 빨리 찾을 수 있게 할 수 있다. DB의 고급 퍼포먼스 성능 튜닝과 관련된 작업 데이터베이스내의 테이블에서 원하는 정보를 좀더 빨리 찾아줄수 있게 데이터의 위치 정보를 모아놓은 데이터베이스내의 객체 object이다 DB의 전반적인 성능의 핵심이 되고 반드시 알아야 할 기술 *인덱스는 정렬되어 있다. 예1) 사진에서 원하는 데이터를 찾을때 예2) 책에서 책뒷부분의 인덱스 페이지 table scan -- 전부다 검색 index seek -- 원하는 페이지만 검색 ===================================.. 2010. 11. 9. DB 설계시 정규화 정규화(normalization)이란 무엇인가? DB 설계란 자료의 중복성과 비정규성을 제거하고 검색키를 설정하기 위해 데이타베이스의 logical schema를 작성하는 것입니다. 데이타베이스 설계시 가장 중요한 관심사는 릴레이션 구조를 결정하는 것이라고 할 수 있다. 데이타베이스에 어떤 릴레이션을 두고, 그 릴레이션에 어떠한 속성을 포함시킬 것인지는 데이타관리 및 사용의 성패에 큰 영향을 미친다. 바로 정규화이론은 어떠한 릴레이션 구조가 바람직한 것인지, 바람직하지 못한 릴레이션을 어떻게 분해하여야 하는지에 관한 구체적인 판단기준을 제공한다. 정규화의 목적 자료정규화작업의 가장 큰 목적은 자료저장의 중복성 배제이다. 정규화이론에서는 릴레이션의 형태가 여러단계로 구분된다. 가장 기본적인 정규화조건도 만.. 2010. 11. 9. SQL튜닝 - 드라이빙 테이블 순서 관련(오라클) 안녕하세요. 제가 답변을 드려봅니다. 일반적으로 조인을 할 때, 예를들어 A와 B를 조인할 때 크기가 작은 쪽에서 큰 쪽으로 데이터가 흘러가는게 빠릅니다. 예를들어 보겠습니다. NO EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO 1 7369 SMITH CLERK 7902 1980-12-17 800 20 2 7499 ALLEN SALESMAN 7698 1981-02-20 1600 300 30 3 7521 WARD SALESMAN 7698 1981-02-22 1250 500 30 4 7566 JONES MANAGER 7839 1981-04-02 2975 20 5 7654 MARTIN SALESMAN 7698 1981-09-28 1250 1400 30 6 7698 BLAKE .. 2010. 11. 9. [MSSQL] *=과 LEFT OUTER JOIN의 차이점.. LEFT OUTER JOIN 을 사용 했을때 JOIN 절에 조건식을 넣는것과 JOIN 이후 WHERE을 이용해서 조건식을 넣는것의 차이점 및 *=는 전자를 이야기 한다 ------------------------------------------------------------------------------------------------------- 출처 : http://blog.naver.com/crabz/140023357168 MSSQL의 left outer join과 *= 는 같은 표현이 아닙니다. (전혀 다름) 예를 들어 다음과 같은 테이블이 있습니다. select * from A; YM EMP DEPT 200212 1 40 200212 2 40 200212 3 40 200212 4 40 200.. 2010. 10. 17. [펌] MSSQL 잠금에 관한 고찰(3) - 교착상태(데드락,DeadLock)에 대하여 원문출처 : http://kuaaan.tistory.com/100 ------------------------------------------ DeadLock이란 둘 이상의 세션이 서로 맞물려 차단된 상태를 말한다. DeadLock이 발생하면 영원히 지속되기 때문에 SQL 서버가 자동으로 찾아내어 해제시켜 준다. DeadLock에는 두가지 종류가 있다. 1. 순환 교착 (Cycle Deadlock) 교착상태를 설명할 때 보통 예로 드는 것이 이 "Cycle DeadLock"이다. 두 세션이 필요한 리소스를 얻기 위해 서로 상대방이 Lock을 풀기를 기다리는 상태라고 설명할 수 있다. 예를 들면 다음과 같다. view plaincopy to clipboardprint? -- 세 션 1 BEGIN TRAN .. 2010. 6. 17. [펌] MSSQL 잠금에 관한 고찰(2) - 격리 수준(Transaction Isolation Level)에 대하여 원문출처 : http://kuaaan.tistory.com/98 ----------------------------------------- 격리 수준(Transaction Isolation Level)이란 SQL Server에서 잠금(Lock)을 어떤 식으로 적용할 것인가에 관한 얘기이다. 주로 SELECT시의 Lock을 어떻게 걸 것이냐에 따라 격리 수준이 구분지어진다. 1. READ COMMITTED 글자 그대로 해석하면 "커밋된 데이터만 읽을 수 있는" 격리수준이다. SQL Server의 기본 격리수준으로서 SELECT 실행시 공유잠금을 건다. 이 격리수준에서는 SELECT를 시도하려는 DATA에 다른 트랜잭션에서 업데이트를 진행한 경우, 배타적 잠금(X-Lock)이 걸린 데이터에 공유잠금(S-Lo.. 2010. 6. 17. [펌] MSSQL 잠금에 관한 고찰(1) - 잠금(Lock) 매커니즘에 대하여 원문 출처 : http://kuaaan.tistory.com/97 ----------------------------------------------- 데이터의 무결성을 보장하기 위해 SQL Server에서는 데이터에 Lock을 건다. 사흘에 걸쳐 책을 읽고 테스트를 하면서 공부한 끝에 이 Lock의 매커니즘을 어느정도 이해할 수 있게 되었다. 이에 이해한 내용을 정리해보고자 한다. 1. 잠금(Lock)의 개념 데이터에 잠금(Lock)을 건다고 하면 언뜻 생각하기엔 데이터가 들어있는 방에 들어가지 못하게 방문을 걸어 잠근다는 느낌이 들지만, 사실은 방문에 "이 방에는 U-Lock이 걸려있음" 이라고 써 붙이는 개념에 가깝다. 그 방에 누군가 SELECT를 시도한다면, 시도하는 사람은 그 방에 또 "S-L.. 2010. 6. 17. MSSQL2005 외부접속, 외부연결 방법 SQL2005를 설치하면 SQL SERVER 노출영역 구성이 보일겁니다.( 시작 - 프로그램 - SQL SERVER 2005 - 구성도구 ) 실행하면 위의 화면이 나옵니다. 빨간네모를 클릭해주세요. 그럼 위와 같은 화면이 나옵니다. 이 화면에서 TCP/IP만 사용으로 합니다. 그런 후 확인 누르고 창을 닫습니다. 시작 - 프로그램 - SQL SERVER 2005 - 구성 에 보면 구성관리자라고 있을 겁니다. 그걸 실행해주면 위의 화면이 나옵니다. TCP/IP를 더블클릭해주세요 아래의 화면이 나옵니다. IP주소로 탭을 변경 해 주시고 아래와 같이 원하는 포트(기본은 1433)로 변경해줍니다. 저같은 경우는 사용을 꼭 "예"로 안해도 외부 접속이 되더군요. 혹시 안되시는분은 사용을 "예"로 해보시길 바랍니다.. 2010. 6. 17. [MSSQL] BAK 파일을 이용한 DB 복원 -- BAK 파일에서 mdf, ldf와 정보를 볼수 있다. RESTORE FILELISTONLY FROM DISK = 'd:\201004270200.BAK' --백업파일위치 RESTORE DATABASE up FROM DISK = '201004270200.BAK' WITH MOVE 'backup_data' TO 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data\backup.mdf', --데이터파일 -- LogicalName(데이터) --저장할 경로 MOVE 'backup_log' TO 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data\backup.ldf' --로그파일 -- LogicalName(로그.. 2010. 5. 18. [오라클] 에러 메세지와 에러의 이유 http://mis3nt.gnu.ac.kr/PublicData/Oracle11gDoc/server.111/b28278/e0.htm 2010. 4. 5. [MSSQL] 2000, 2005 등 에서 BAK로 복원 하기 출처 : http://mcpicdtl.blogspot.com/2009/12/mssql-restore-bak-mssql-2000-2005-2008.html 실행 전 주의 사항 -3. 복원의 DB명은 미리 생성하지 말것(Unique DB Name) 1. 확인1 RESTORE HEADERONLY FROM DISK = '(A)backup file path and file name' 2. 확인2 RESTORE FILELISTONLY FROM DISK = '(A)backup file path and file name' 3. 복원 RESTORE DATABASE DB명(확인1에 DatabaseName컬럼) FROM DISK = '(A)backup file path and file name' WITH MOVE '(C)논.. 2010. 1. 29. [MSSQL] 테이블 데이터 인서트문으로 백업 받기(펌) 출처 : http://sqler.pe.kr/web_board/view_list.asp?id=664&read=3618&pagec=&found=is&part=myboard7&ser=yes ===================================================================================================== if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[sp_generate_insert_script]') and objectproperty(id, N'IsProcedure') = 1) drop procedure [dbo].[sp_generate_insert_script] g.. 2009. 11. 16. [MSSQL2005] 사용자와 스키마의 관계 SQL Server 2005에서는 데이터베이스 사용자와 스키마 간의 암시적 연결을 끊습니다. 스키마 정의 스키마는 하나의 네임스페이스를 구성하는 데이터베이스 엔터티 모음입니다. 네임스페이스는 모든 요소가 고유한 이름을 갖는 집합입니다. 예를 들어 이름 충돌을 피하려면 같은 스키마 안에 이름이 같은 테이블이 두 개 있으면 안 됩니다. 두 개의 테이블에 동일한 이름을 사용하려면 테이블이 각각 서로 다른 스키마에 속해 있어야 합니다. 참고: 데이터베이스 도구에 대해 설명할 때는 "스키마"가 스키마 또는 데이터베이스의 개체에 대해 설명하는 카탈로그 정보를 나타내기도 합니다. Analysis Services에 대해 설명할 때는 "스키마"가 큐브 및 차원 같은 다차원 개체를 나타냅니다. SQL Server 2000.. 2009. 8. 14. 오라클 인스턴트 클라이언트 + 파워빌더 가능 개인적으로 리포팅 해놓는 글 입니다 ^^.. 가끔 까먹는지라.. 파워빌더 11.5를 기준으로 오라클의 클라이언트 인스톨없이 접속이 가능 했음을 오늘의 테스트로 알게 되었습니다. 뭐 예전에도 해봤는데 따로 리포팅 해놓지를 않아서 다시 해보게 되었네요. 오라클 사이트에서 인스턴트 오라클 클라인언트를 다운로드 한 후 프로그램과 같이 배포 하면 됩니다. ( 단 오라클 인스턴트 클라이언트의 용량이 100메가에 육박 하므로 조금 안습.. ) 물론 배포할때 tnsnames.ora가 반드시 포함 되어야 합니다. 그럼 미래의 나에게 이 글을 바칩니다. ^^; 2009. 4. 27. 오라클 DB 수동생성(펌) D:\ dbca 이렇게 명령어를 치거나 시작 --> 오라클 --> 구성 및 이전 툴 --> Database Configuration Assistant 를 누르시면 같은 기능이 됩니다. 물론 GUI환경이기 때문에 무지 쉽게 하실 수 있습니다. 그리고 오라클에서도 수동으로 생 성하는 것보다는 DBCA 를 사용하는 것을 권장 하구요^^ 지금 부터는 수동으로 메뉴얼하게 만드는 법을 가르쳐 드릴께요~ 1. initSID.ora 파일은 데이타베이스 설정을 초기화합니다. initSID.ora 파일에 나열된 parameter들은 순서대로 정렬할 필요는 없지만 특정parameter가 두번 이상 나열되면 마지막 설정이 사용됩니다.. 그래서 Oracle 9i Reference에서는 이러한 중복을 방지할수 있도록 par.. 2009. 4. 23. 오라클 캐릭터셋 변경 오라클을 다른 운영체제에 Import시 캐릭터셋을 꼭 확인 해본다. 아래는 캐릭터셋 변경 방법 캐릭터셋 확인 방법 SELECT NAME, VALUE$ FROM SYS.PROPS$ WHERE NAME = 'NLS_LANGUAGE' OR NAME = 'NLS_TERRITORY' OR NAME = 'NLS_CHARACTERSET' 1. 9i이상 캐릭터셋 변경 sqlplus as sysdba 로 접속 후 UPDATE SYS.PROPS$ SET VALUE$ ='KO16MSWIN949' WHERE NAME ='NLS_CHARACTERSET' COMMIT; 오라클 서버를 셧다운 후 리스타트 한다. 2. 8i 캐릭터셋 변경 SHUTDOWN IMMEDIATE; STARTUP MOUNT; ALTER SYSTEM ENA.. 2009. 4. 23. Vmware + 우분투(리눅스) + 오라클10g 드디어 성공.. 아이고 힘들어 죽겠네. 나중을 위해 개인적으로 레포팅을 해놓자. 1. vmware나 가상 머신으로 우분투를 깔때는 적당한 하드용량을 배분할것(특히 스왑용량은 충분히!) 2. 오라클 깔때 10g 인스톨하던중 Linking phase fails for 10gR2 on Ubuntu 6.06: undefined ref to 'nnfyboot' 버그 발생시 http://forums.oracle.com/forums/thread.jspa?threadID=413032&tstart=0 사이트를 참고하여 해결 3. 우분투에 오라클10g를 인스톨 할경우 아래의 사이트의 설정을 따라 하여 보자. http://blog.naver.com/wjwscv?Redirect=Log&logNo=20052759427 4. 굳이 우분투에 오라.. 2008. 10. 3. 오라클 Win 2000,XP에서 오라클 8.1.7이나 8.1.6을 Install 문제 pentium4에서는 오라클 8.1.7이나 8.1.6을 install할려고 하면 처음 autorun에서 화면이뜨고 install을 하면 화면이 죽어버립니다. 이유는 기존 8.1.7이나 8.1.6에는 jRE1.1.7이 들어 있는데 이것이 문제인거 같습니다. SUN사 측에서도 pentium4를 쓸경우는 jre1.1.8이상을 쓰라고 되어 있습니다. 해결방안은 우선 1. 기존 가지고 있는 CD를 CD-ROM에 삽입해서 깔 수는 없습니다. CD의 전부를 하드에 하드 copy 하십시요. 2. http://ofs.gwu.edu/ofs/application/req.html 사이트에 가셔서 symcjit.dll를 다운받으십시오 3. 하드에 옮겨놓은 오라클 폴더에 들어가서 stage/Components/oracle.swd.. 2008. 7. 25. 이전 1 2 다음